简介
Mach-O二进制文件被组织成段。每个部分包含一个或多个部分。段的大小由它所包含的所有部分的字节数来度量,并四舍五入到下一个虚拟内存页边界。因此,一个段总是4096字节或4千字节的倍数,其中4096字节是最小大小。
mach-o文件格式,分别存储什么样的数据
#define MH_OBJECT 0x1 /* 目标文件*/ .o .a/framework静态库(静态库即多个.o存放在一起实现特定的功能)
#define MH_EXECUTE 0x2 /* 可执行文件 */ .app .out
#define MH_FVMLIB 0x3 /* fixed VM shared library file */
#define MH_CORE 0x4 /*核心转储文件 */
#define MH_PRELOAD 0x5 /* preloaded executable file */
#define MH_DYLIB 0x6 /* dynamically bound shared library */ .dylib 动态库
#define MH_DYLINKER 0x7 /* dynamic link editor */ usr/bin/dyld 动态链接器
#define MH_BUNDLE 0x8 /* dynamically bound bundle file */
#define MH_DYLIB_STUB 0x9 /* shared library stub for static */
/* linking only, no section contents */
#define MH_DSYM 0xa /* companion file with only debug */ .dYSM/Contents/Resources/DWARF/MyApp 二进制符合表
/* sections */
#define MH_KEXT_BUNDLE 0xb /* x86_64 kexts */
segment-section格式 原因
之所以按照 Segment -> Section 的结构组织方式,是因为在同一个 Segment 下的 Section,可以控制相同的权限,也可以不完全按照 Page 的大小进行内存对其,节省内存的空间。而 Segment 对外整体暴露,在程序载入阶段映射成一个完整的虚拟内存,更好的做到内存对齐
struct segment_command_64 {
uint32_t cmd; /* LC_SEGMENT_64 */
uint32_t cmdsize; /* section_64 结构体所需要的空间 */
char segname[16]; /* segment 名字,上述宏中的定义 */
uint64_t vmaddr; /* 所描述段的虚拟内存地址 */
uint64_t vmsize; /* 为当前段分配的虚拟内存大小 */
uint64_t fileoff; /* 当前段在文件中的偏移量 */
uint64_t filesize; /* 当前段在文件中占用的字节 */
vm_prot_t maxprot; /* 段所在页所需要的最高内存保护,用八进制表示 */
vm_prot_t initprot; /* 段所在页原始内存保护 */
uint32_t nsects; /* 段中 Section 数量 */
uint32_t flags; /* 标识符 */
};
struct section_64 {
char sectname[16]; /* Section 名字 */
char segname[16]; /* Section 所在的 Segment 名称 */
uint64_t addr; /* Section 所在的内存地址 */
uint64_t size; /* Section 的大小 */
uint32_t offset; /* Section 所在的文件偏移 */
uint32_t align; /* Section 的内存对齐边界 (2 的次幂) */
uint32_t reloff; /* 重定位信息的文件偏移 */
uint32_t nreloc; /* 重定位条目的数目 */
uint32_t flags; /* 标志属性 */
uint32_t reserved1; /* 保留字段1 (for offset or index) */
uint32_t reserved2; /* 保留字段2 (for count or sizeof) */
uint32_t reserved3; /* 保留字段3 */
};
mach-o 文件的结构组成
- Header: 保存了Mach-O的一些基本信息,包括了平台、目标架构、文件类型、LoadCommands的个数等等。 使用otool -v -h a.out查看其内容:
- Load command: 描述文件在虚拟内存中的逻辑与布局
- Raw segment section data: Load command中定义的原始数据 Segment __PAGEZERO。 大小为 4GB,规定进程地址空间的前 4GB 被映射为不可读不可写不可执行。 Segment __TEXT。 包含可执行的代码,以只读和可执行方式映射。 Segment __DATA。 包含了将会被更改的数据,以可读写和不可执行方式映射。 Segment __LINKEDIT。 包含了方法和变量的元数据,代码签名等信息。
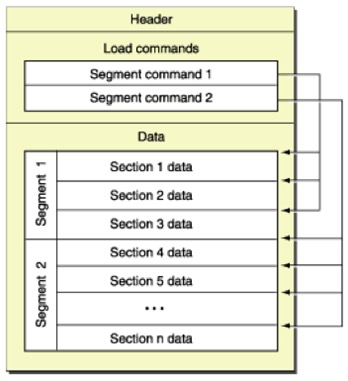
mach-o 文件各个部分意义
__TEXT段中的 Section
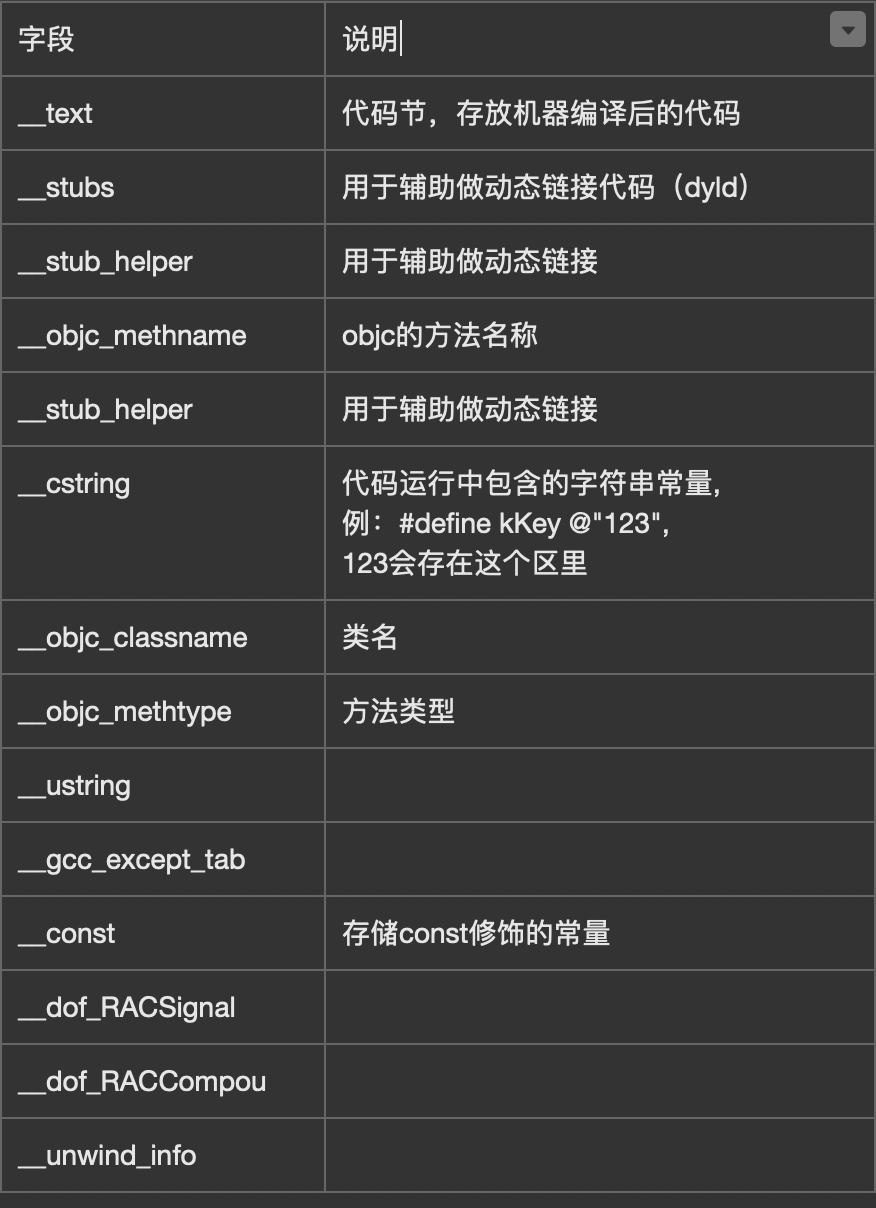

link-map文件格式
使用mach-o文件可以做什么
包体积优化、剔除无用的函数、了解加载流程、好像还可以做符号化(不熟)
如何使用fishhook对C语言函数进行hook,比如NSLog
// 申明一个函数指针,用于保存原NSLog的真实函数地址,其函数签名必须与原函数保持一致。
// 因为hook掉原函数后,在新函数中依然需要调用,不然原有功能就缺失了。
static void (*orig_nslog)(NSString *format, ...);
void my_nslog(NSString *format, ...) {
// 此时,函数体已经交换,该调用实际上用的是NSLog的函数体。
orig_nslog([NSString stringWithFormat:@"我的NSLog: %@", format]);
}
NSLog(@"123");
// 使用rebinding结构体表示一次hook操作,使用rebind_symbols函数进行符号重定向操作。
struct rebinding rebinding_nslog = {"NSLog", my_nslog, (void *)&orig_nslog};
rebind_symbols((struct rebinding [1]){rebinding_nslog}, 1);
NSLog(@"123");
fishhook不能对自定义函数进行hook。
fishhook为什么不能对自定义函数进行hook
如果自定义函数在动态库下面,hook在上层库调用,可以hook,原理: (其实是基于dyld的动态库链接加载顺序,和dyld在mach-o文件的指针修改做到的) App在需要调用系统函数的时候,会在_DATA段建立一个指针。dyld进行动态绑定,将该指针指向一个函数实现体。如,调用NSLog的时候,系统先建立一个函数指针,在dyld动态加载Foundation框架时,将该指针指向NSLog的函数实现体。而fishhook即可以通过修改该指针的指向地址,将其指向替换后的函数实现地址,即达到了hook C语言函数的目的。(fishhook即是针对符号进行重新绑定)
动态链接库里边的C语言函数,其函数的地址指针存放在__DATA.__la_symbol_ptr(懒绑定符号指针)和__DATA.__nl_symbol_ptr(非懒绑定符号指针)这两个section, 而其实现地址可能存在于dylib中, 要等到App启动之后才能明确知道.
fishHook 原理
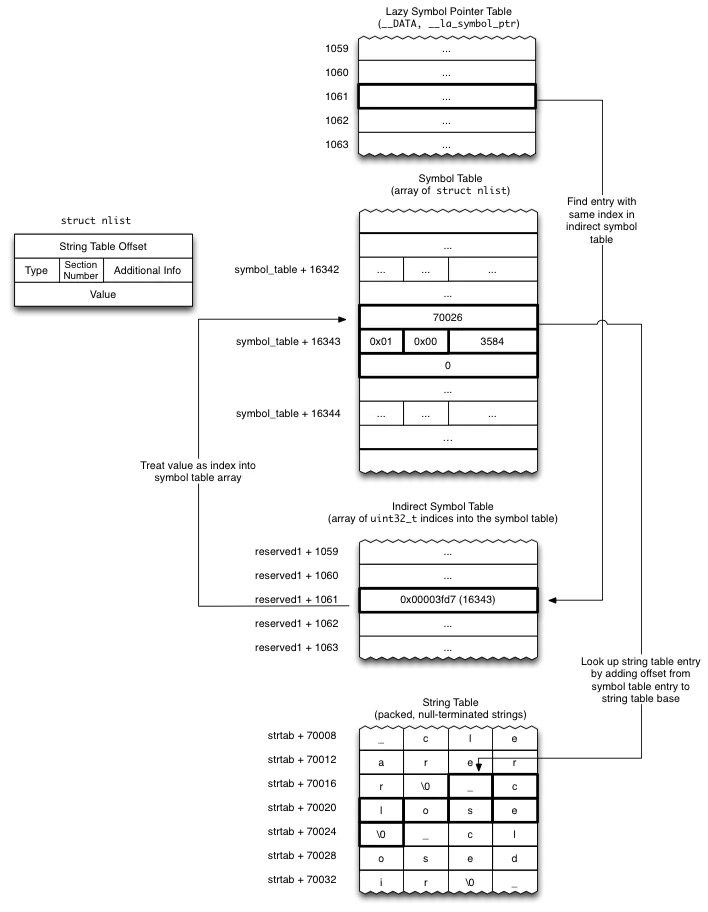
瘦身相关
__objc_classlist 和 __objc_classrefs ,它们分别表示项目中全部类列表和项目中被引用的类列表,那么取两者之差,就能删除一些项目中没使用的类文件。
- 在控制台输入 otool -v -s __objc_classlist 和 otool -v -s __objc_classrefs 命令,逆向 __DATA. __objc_classlist 段和 __DATA. __objc_classrefs 段获取当前所有oc类和被引用的oc类。
- 取两者差集,得到没被引用的类的段地址
- otool -o 二进制文件,获取段信息
- 通过脚本使用没被引用的类的段地址去段信息中匹配出具体类名
如何用 MachO 文件关联类的方法名
常用命令
file
otool(1) 来观察可执行文件的头部 – 规定了这个文件是什么,以及文件是如何被加载的。通过 -h 可以打印出头信息:
- otool -v -h a.out
- otool -v -s __DATA __objc_classlist TYColorTheme 查看 data下 objc_classList
- otool -L xxx 查看动态依赖的库
lipo是管理Fat File的工具,可查看平台列表,提取特定平台,重新打包。一般用于多架构mach-o文件的处理。
- lipo -info xxx 查看架构信息
- lipo -detailed_info xxx 详细信息 等同于 otool -f -V LuckyClient
- lipo -thin armv7 MAMapKit -output MAMapKit.armv7 提取特定架构 (只有mach-o文件指定的平台信息指定了多个平台才可用)
- lipo -create WeChat_arm64 WeChat_armV7 -output WeChat_64_V7 合并多个架构
nm用来显示一个程序包的符号表,默认会显示入口地址、符号类型、符号名。
-
nm -j MAMapKit.armv7 grep png > symbols -j只输出符号名。 - nm -nm TYColorTheme
strip用来删除程序里的符号表。-R指定要删除的符号列表。-S保留其他符号。
- strip -S -R symbols MAMapKit.armv7 -o MAMapKit.armv7.strip
dyld的作用
- 从内核留下的原始调用栈引导和启动自己
- 将程序以来的dylib递归加载进内存,考虑缓存机制
- non-lazy符号立即link到可执行文件,lazy的存表里
- Runs static initializers for the executable
- 找到可执行文件的main函数,准备参数并调用
- 程序执行中负责绑定lazy符号,提供runtime dynamic loading services,提供调试器接口
- 程序main函数return后执行static terminator
- 某些场景下main函数结束后调用libsystem的_exit函数
mach-o 里 stub
Stub代码区是本地源代码调用系统库代码的连接点,当 app 工程中有调用系统函数的代码时,在 app 编译后,那个调用系统函数的处的内存地址便指向了stub代码区 。 app 从本地加载到内存时,使用的系统函数 API 在 app 的可执行文件文件中并没有函数实现,需要dyld动态链接器将系统 API 与系统函数地址进行绑定。 而根据绑定时机不同,绑定分为 app 加载时binding和函数调用时lazy_binding。 下面以lazy_binding绑定方式为例:
- 点击按钮,触发本地函数对系统函数的调用,此时被调用的系统函数指针是指向的stub代码区,
- 在stub代码区的实现中,又将函数指针指向了懒动态符号表。
- 懒动态符号表又将函数指针指向了stub_helper代码区。
- 最后stub_helper代码区通过dyld_stub_binder函数将真实的系统函数内存地址更新到懒动态符号表中。
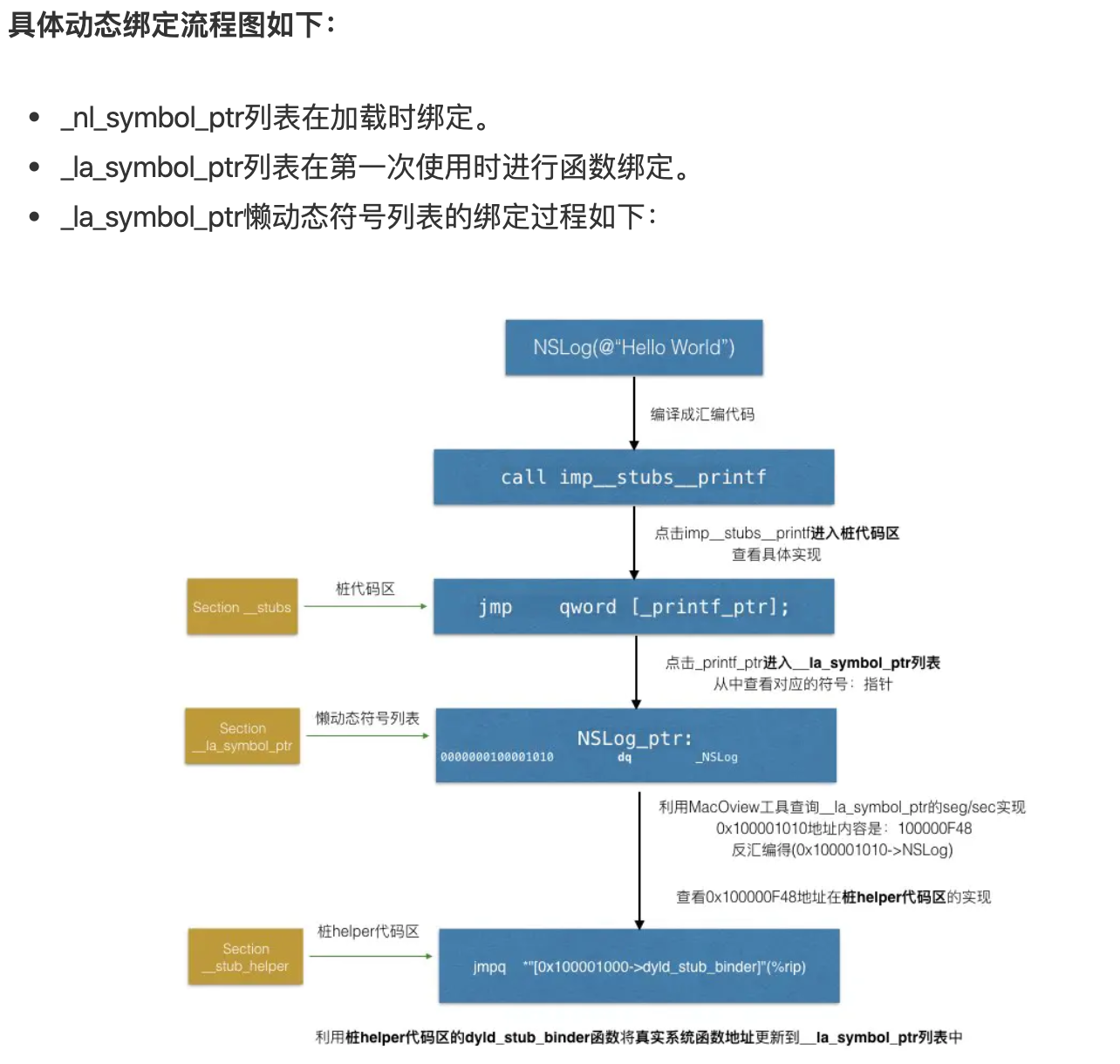
以后慢慢看
https://www.jianshu.com/p/37f10bb70c50
__TEXT.__stubs
总结一下 Stub 机制。设置函数占位符并采用 lazy 思想做成延迟 binding 的流程。在 macOS 中也是如此,外部函数引用在 __DATA 段的 __la_symbol_ptr 区域先生产一个占位符,当第一个调用启动时,就会进入符号的动态链接过程,一旦找到地址后,就将 __DATA Segment 中的 __la_symbol_ptr Section 中的占位符修改为方法的真实地址,这样就完成了只需要一个符号绑定的执行过程。
二进制重排
原因
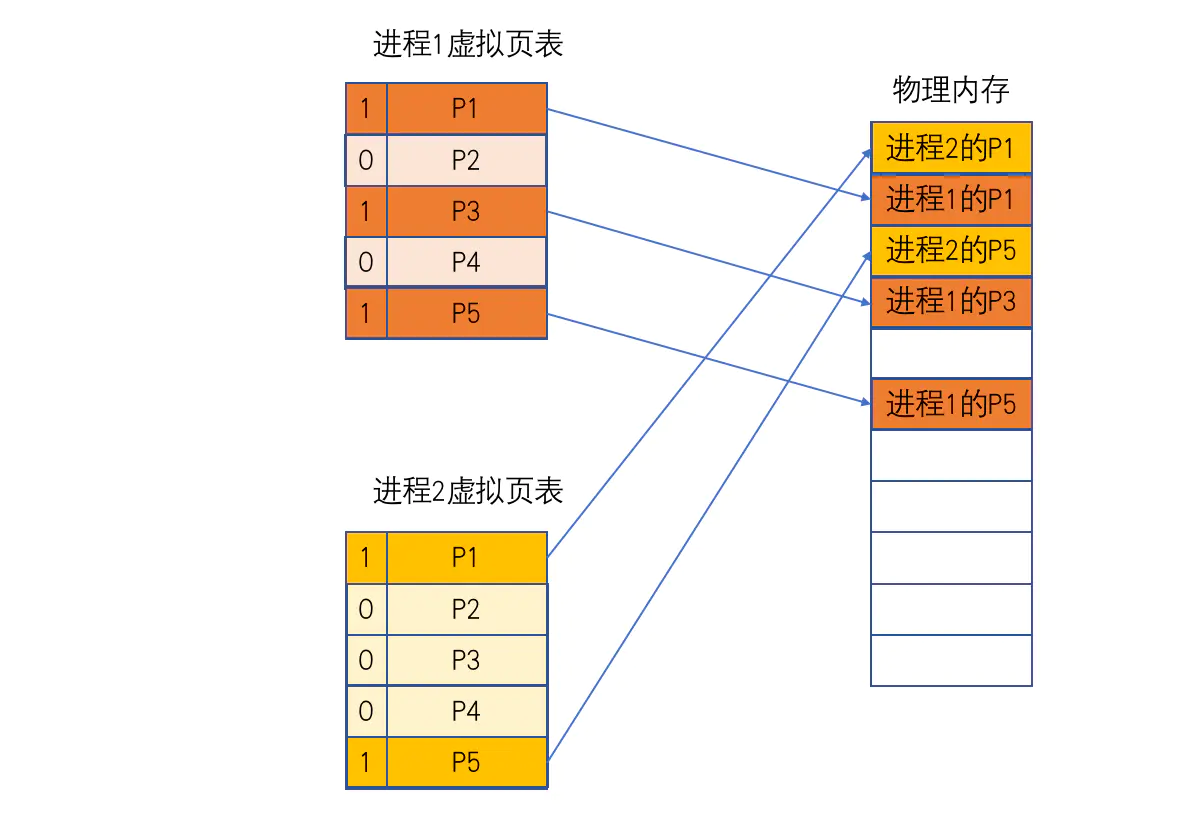
在应用加载时候不会把所有数据放内存中,因为数据是懒加载,当进程访问虚拟地址时候,首先看页表,如果发现该页表数据为0,说明该页面数据未在物理地址上,这个时候系统会阻塞该进程,这个行为就叫做页中断(page Fault),也叫缺页异常,然后将磁盘中对应页面的数据加载到内存中,然后让虚拟内存指向刚加载的物理内存,将数据加载到内存中时候,如果有空的内存空间,就放空的内存空间中,如果没有的话,就会去覆盖其他进程的数据,具体怎么覆盖操作系统有一个算法,这样永远都会保证当前进程的使用,这就是灵活管理内存。
ASLR(地址空间随机化),就是进程每次加载的时候都会给一个随机的偏移量,这样就保证每次加载进程时候虚拟内存也在变化,iOS从iOS4就开始了
虚拟内存中有个很大问题就是缺页中断,这个操作很耗时间,并且iOS不仅仅是将数据加载到内存,还要对这页做签名认证,所以iOS耗时比较长,并且每页耗时有很大差距,0.1ms到0.8毫秒,使用过程中可能时间段感觉不到,但是启动时候会有很多数据要加载,这样就会导致耗时很长,假如我们启动时候在不同页面,因为代码在machO的位置不是根据调用瞬间,而是通过文件编译的位置来的,有可能启动时候在运行时候会调用很多次page Fault,那么如果我们把所有启动时候的代码都放在一页或者两页,这样就很大程度上优化启动速度,这种方法就叫做二进制重拍
进程如果能直接访问物理内存无疑是很不安全的,所以操作系统在物理内存的上又建立了一层虚拟内存。为了提高效率和方便管理,又对虚拟内存和物理内存又进行分页(Page)。当进程访问一个虚拟内存Page而对应的物理内存却不存在时,会触发一次缺页中断(Page Fault),分配物理内存,有需要的话会从磁盘mmap读人数据。
通过App Store渠道分发的App,Page Fault还会进行签名验证,所以一次Page Fault的耗时比想象的要多:

MMU 将会触发 page fault 中断来加载对应的物理页,建立起虚拟内存和物理内存的映射关系
App 在启动时,需要执行各种函数,我们需要读取 TEXT 段代码到物理内存中,这个过程会发生缺⻚中断,由于启动时所需要执行的代码分布在 TEXT 段的各个部分,会读取很多⻚面,导致启动时 Page Fault 数量非常多。与直接访问物理内存不同, page fault 过程大部分是由软件完成的,消耗时间比较久,所以是影响启动性能的一个关键指标。
编译器在生成二进制代码的时候,默认按照链接的Object File(.o)顺序写文件,按照Object File内部的函数顺序写函数。
静态库文件.a就是一组.o文件的ar包,可以用ar -t查看.a包含的所有.o。
代码
XCode使用的链接器叫做ld,ld有个参数叫order_file,只要有这个文件,我们可以将文件的路径告诉XCode,在order_file文件中把符号的顺序写进去,XCode编译的时候就会按照文件中的符号顺序打包成二进制可执行文件。
添加order file,我们创建一个hank.order文件,在文件中写入

然后放到工程的根目录中,然后在Build setting里面搜下order file,然后在后面将该文件地址添加进去,Xcode在编译时候就会按照order文件中的符号顺序链接代码了 编译,重新看一下LinkMap-normal-arm64.txt文件,顺序一致
获取APP启动时候调用的所有方法
- fishHook去hook 系统的 objc_msgSend这个函数,只能通过汇编
- clang插装形式 查看这个
clang插庄逻辑 SanitizerCoverage采集调用函数信息 我们通过 SanitizerCoverage 采集调用函数信息, SanitizerCoverage 内置在LLVM中,可以在函数、基本块和边界这些级别上插入对用户定义函数的回调,属于静态插桩,代码会在编译过程中插入到每个函数中,详细介绍可以在 Clang 11 documentation 找到。
在 build settings 里的 “Other C Flags” 中添加 -fsanitize-coverage=func,trace-pc-guard。如果含有 Swift 代码的话,还需要在 “Other Swift Flags” 中加入 -sanitize-coverage=func 和 -sanitize=undefined。需注意,所有链接到 App 中的二进制都需要开启 SanitizerCoverage,这样才能完全覆盖到所有调用。
开启后,函数的调用 都会执行 void __sanitizer_cov_trace_pc_guard(uint32_t *guard) {} 回调,效果类似我们对 objc_msgSend 进行 Hook插桩,但该回调不止局限于 OC 函数,还包括 Swift、block、C等。
dyld 每链接一个开启 SanitizerCoverage 配置的 dylib 都会执行一次 __sanitizer_cov_trace_pc_guard_init,start 和 stop 之间的区间保存了该 dylib 的符号个数,我们通过设置静态全局变量 N 可统计所有 dylib 的符号。
link map
- Build Settings搜索link map 改成YES
- 修改路径, build
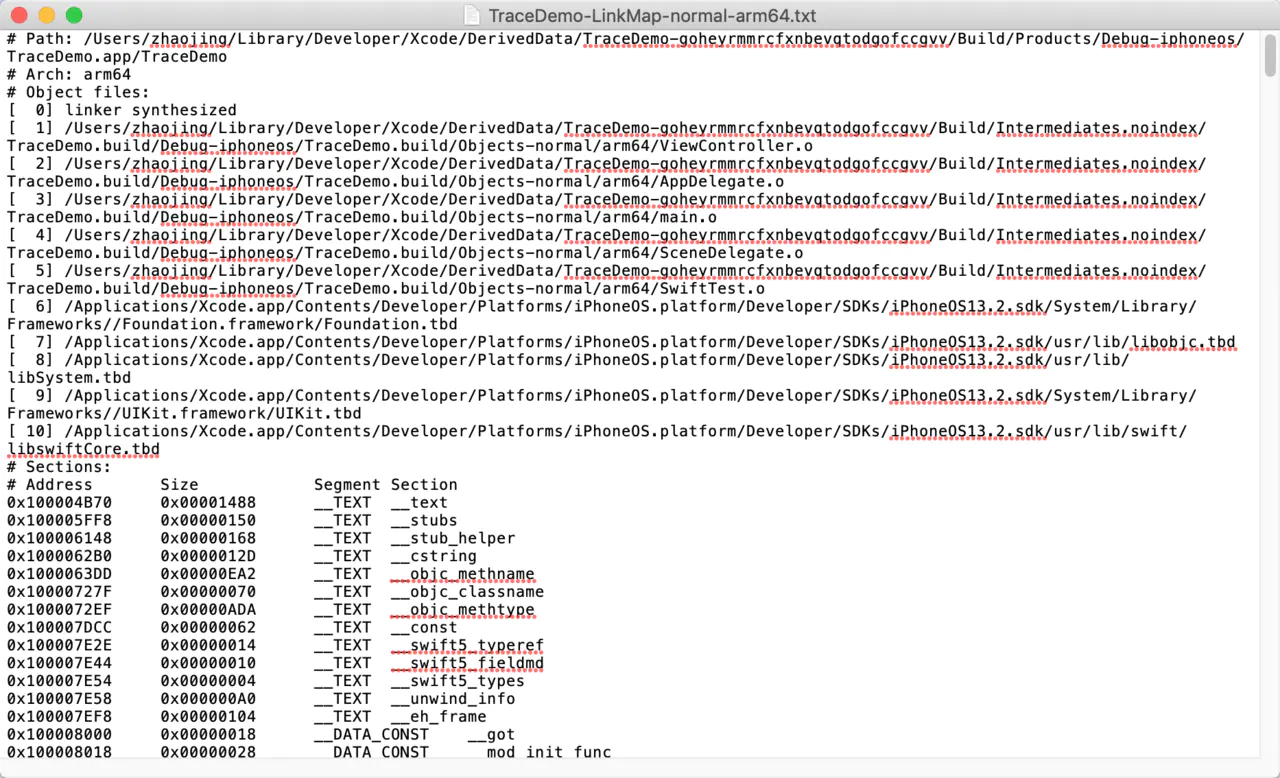 分为以下几部分
分为以下几部分
- Object files:就是链接了哪些.o文件
- Sections: mach-o,涉及address size segment section等
- Symbols:
- Address:方法代码的地址
- Size:方法占用的空间
- File:文件的编号
- Name:.o文件里面的方法符号