内存对齐方式
“对齐系数”(也叫对齐模数)。程序员可以通过预编译命令#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是你要指定的“对齐系数”。
1、数据成员对其规则:结构体(struct)或联合体(union)的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小或者成员的子成员大小(只要该成员有子成员,比如数组、结构体等)的整数倍开始。 eg: int为4字节,则要从4的整数倍地址开始存储
2、结构体作为成员:如果一个结构体内部包含其他结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储。 eg: struct a里包含struct b,b中包含其他char、int、double等元素,那么b应该从8(double的元素大小)的整数倍开始存储
3、收尾工作:结构体的总大小,也就是sizeof的结果,必须是其内部最大成员的整数倍,不足的需要补齐。
为啥要对齐
经过内存对齐之后可以发现,size反而变大了。那为什么还要进行内存对齐呢?因为cpu存取内存并不是以byte为单位的,而是以块为单位,每块可以为2/4/8/16字节,每次内存存取都会产生一个固定的开销,减少内存存取次数将提升程序的性能。所以 CPU 一般会以 2/4/8/16/32 字节为单位来进行存取操作。我们将上述这些存取单位也就是块大小称为(memory access granularity)内存存取粒度。如果没有内存对齐,会大大增加cpu在存取过程中的消耗 为了在访问对象的时候提高访问效率(空间换时间),同时也可以有效避免访问溢出。
struct ZHYStruct3 {
char a; // 1 从初始位置开始排 占0位
char b; // 1 从1的倍数开始排 占1位
struct ZHYStruct1 c; //16 从8的倍数开始排 占8-23位
double d; //8 从8的倍数开始排 占24-32位
int e; //4 从4的倍数开始 占36-39位
long long f; //8 从8的倍数开始 占40-48位
} MyStruct3;
Person *p = [Person alloc];
p.name = @"Kaemi"; // NSString 8
p.age = 18; // int 4
p.height = 188; // long 8
p.hobby = @"game"; // NSString 8
/// 打印结果: 申请内存大小为:40---系统开辟内存大小为:48
NSLog(@"申请内存大小为:%lu——-系统开辟内存大小为:%lu",class_getInstanceSize([p class]),malloc_size((__bridge const void *)(p)));
对象销毁
对象的销毁虽然消耗资源不多,但累积起来也是不容忽视的。通常当容器类持有大量对象时,其销毁时的资源消耗就非常明显。同样的,如果对象可以放到后台线程去释放,那就挪到后台线程去。这里有个小 Tip:把对象捕获到 block 中,然后扔到后台队列去随便发送个消息以避免编译器警告,就可以让对象在后台线程销毁了。
RAM概念
RAM 随机存取存储器(random access memory,RAM)又称作“随机存储器”,是与CPU直接交换数据的内部存储器,也叫主存(内存)。
CPU 寻址方式 内存分页 内存压缩
- 内存可以被看作一个数组,数组元素是一个字节大小的空间,而数组索引则是所谓的物理地址(Physical Address)。最简单最直接的方式,就是 CPU 直接通过物理地址去访问对应的内存,这样也被叫做物理寻址。
- 现代处理器使用的是虚拟寻址的方式,CPU 通过访问虚拟地址(Virtual Address),经过翻译获得物理地址,才能访问内存。这个翻译过程由 CPU 中的内存管理单元(Memory Management Unit,缩写为 MMU)完成。
- 虚拟内存和物理内存都被分割成相同大小的单位,物理内存的最小单位被称为帧(Frame),而虚拟内存的最小单位被称为页(Page)。内存分页最大的意义在于,支持了物理内存的离散使用,方便管理 (现在基本都是16kb,老设备是8kb)
- 移动设备基本没有内存交互机制 - 移动设备上的大容量存储器通常是闪存(Flash),它的读写速度远远小于电脑所使用的硬盘,这就导致了在移动设备就算使用内存交换机制,也并不能提升性能。
- 当物理内存不够用时,iOS 会将部分物理内存压缩,在需要读写时再解压,以达到节约内存的目的。而压缩之后的内存,就是所谓的 compressed memory。
- 进行缓存更推荐使用 NSCache 而不是 NSDictionary,就是因为 NSCache 不仅线程安全,而且对存在 compressed memory 情况下的内存警告也做了优化, (如果dict是压缩内存,收到内存警告后,尝试释放掉dict,需要先解压,反倒增大了内存,造成oom)
二进制重排相关可以看mach-o相关
- 在应用加载时候不会把所有数据放内存中,因为数据是懒加载,当进程访问虚拟地址时候,首先看页表,如果发现该页表数据为0,说明该页面数据未在物理地址上,这个时候系统会阻塞该进程,这个行为就叫做页中断(page Fault),也叫缺页异常,然后将磁盘中对应页面的数据加载到内存中,然后让虚拟内存指向刚加载的物理内存,将数据加载到内存中时候,如果有空的内存空间,就放空的内存空间中,如果没有的话,就会去覆盖其他进程的数据,具体怎么覆盖操作系统有一个算法,这样永远都会保证当前进程的使用,这就是灵活管理内存。
- ASLR(地址空间随机化),就是进程每次加载的时候都会给一个随机的偏移量,这样就保证每次加载进程时候虚拟内存也在变化,iOS从iOS4就开始了
dirty memory 与clean meory 如何区分
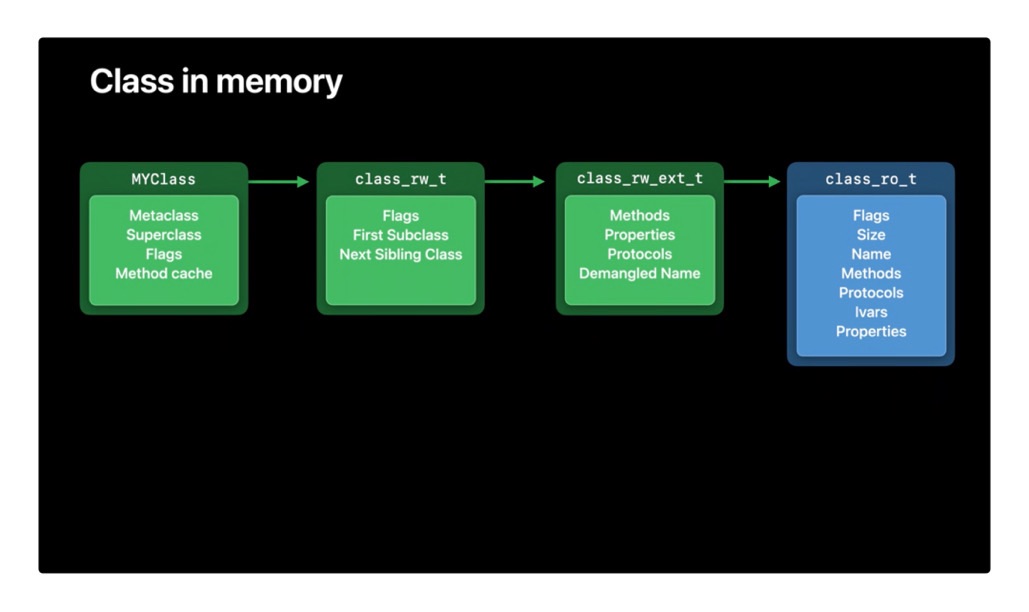
clean memory加载后不会发生变化, class_ro_t属于clean memory,(新创建的固定长度的数组,预先占用的内存也是clean memory) 只读的,收到内存警告后可以由系统进行销毁,再次创建。 Dirty memory是运行时进行修改的内存块。类一旦被加载,就是dirty memory。runtime给类动态添加方法,都是操作的dirty memory. class_rw_t属于 dirty memory, 对开发者来说,越多的clean memory,越好 Dirty memory 比clean 更昂贵,它需要更多的内存信息,并且只要进程正在运行,就必须保留它。 class_rw_t是在 runtime期间创建的,它将class_ro_t内容copy一份,再将类的分类,动态加载的属性、方法、协议添加进去。苹果在iOS14 将动态部分提取出来,称为 class_rw_ext_t,可以吧90%的类优化为clean memory 在系统层面上节约了14MB的内存。
脏内存(Dirty Memory):,主要包括:
- 所有堆上的对象
- 图片解码缓冲数据(Decoded image buffers)
- Frameworks 中的 DATA 和 DATA_DIRTY部分 干净内存(Clean Memory):可以被系统主动回收的内存空间且在需要时能重新加载的数据,主要包括:
- Memory mapped files
- Frameworks 中的 __DATA_CONST 部分
- 应用的二进制可执行文件
iOS的内存分布
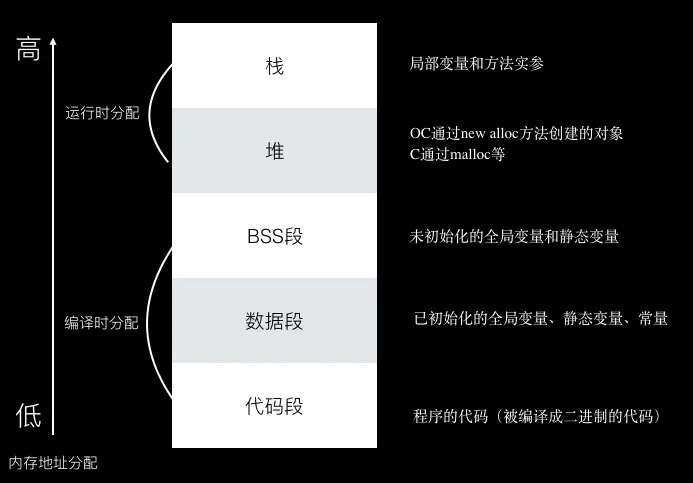
代码段(区)、数据段(区)、全局静态区、堆、栈 全局区又可分为:未初始化全局区: bss段 初始化全局区:data段 如下图中的 数据段+bss段 = 上面的数据段+全局静态区, 或者还有叫(常量区+全局区(静态区))的一个意思
mach-o的__Data下(__data和__bss)会放入数据区和 全局静态区
内存管理
脏内存压缩技术——Compressed Memory 内存警告机制——Responding to Memory Warnings 低内存回收机制——Jetsam Jetsam是 iOS 操作系统为了控制内存资源过度使用而采用的一种资源管控机制 Jetsam 维护了一个优先级队列 内核会调起一个内核优先级最高(95 /* MAXPRI_KERNEL */ 已经是内核能给线程分配的最高优先级了)的线程, 这个线程会维护两个列表,一个是基于优先级的进程列表,另一个是每个进程消耗的内存页的列表。与此同时,它会监听内核 pageout(内存守护程序) 线程调用给每个app进程发送的内存压力通知,获取内存使用情况,在内存告急时向每个进程转发内存警告,也就是触发 didReceiveMemoryWarning 方法。 杀掉应用,触发 OOM,主要是通过 memorystatus_kill_on_VM_page_shortage,有同步和异步两种方式。同步方式会立刻杀掉进程,先根据优先级,杀掉优先级低的进程;同一优先级再根据内存大小,杀掉内存占用大的进程。而异步方式只会标记当前进程,通过专门的内存管理线程去杀死。
内存压力通知和状态是通过libdispatch来做的,可以研究一下_dispatch_source_type_memorypressure 和__dispatch_source_type_memorystatus
内存释放
分为两种:立即释放、自动释放 立即释放: [object relase] 后引用计数=0,会直接触发这个对象的dealloc,然后一系列runtime 的release相关调用后,释放内存 自动释放:被autorelease 或autoreleasepool包裹的,它会在距离它最近一次的自动释放池被清空(Pool drain)后才会进行[object release]将计数器-1。(基于runloop的事件循环来做的,runloop的清空autoreleasepool,被指定为优先级最低)
autoreleasepool
内部各种方法调用参考链接:https://draveness.me/autoreleasepool/
- 系统在主线程的RunLoop里注册了两个Observer,回调都是_wrapRunLoopWithAutoreleasePoolHandler, 第一个监听的是kCFRunLoopEntry,回调内会调用_objc_autoreleasePoolPush()创建一个自动释放池。优先级最高,第二个observer,监听了两个事件:
- 准备进入休眠(kCFRunLoopBeforeWaiting),此时调用 _objc_autoreleasePoolPop()和 _objc_autoreleasePoolPush()来释放旧的池并创建新的池。
- 即将退出Loop(kCFRunLoopExit),此时调用 _objc_autoreleasePoolPop()释放自动释放池。这个 observer 的优先级最低,确保池子释放在所有回调之后。
-
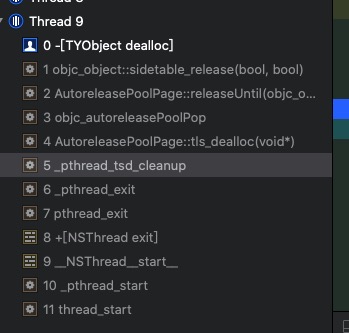
每一个线程都会维护自己的AutoReleasePool. 而每一个AutoReleasePool都会对应唯一一个线程,但是线程可以对应多个AutoReleasePool。(通过在异步代码里添加断点,然后lldb输入:watchpoint set variable temp, 查看控制台输入,可看出线程执行结束时,会先调用[NSthread exit],然后执行_pthread_tsd_cleanup,清除当前线程的有关资源,然后调用tls_dealloc,也就是把当前线程关联的AutoReleasePool释放掉,最后调用weak_clear_no_lock清除指针。
- 每一个自动释放池都是由一系列的 AutoreleasePoolPage 组成的,并且每一个 AutoreleasePoolPage 的大小都是 4096 字节(16 进制 0x1000),内部变量占用56个字节。
- 自动释放池是由 AutoreleasePoolPage 以双向链表的方式实现的
- 当对象调用 autorelease 方法时,会将对象加入 AutoreleasePoolPage 的栈中
- 调用 AutoreleasePoolPage::pop 方法会向栈中的对象发送 release 消息
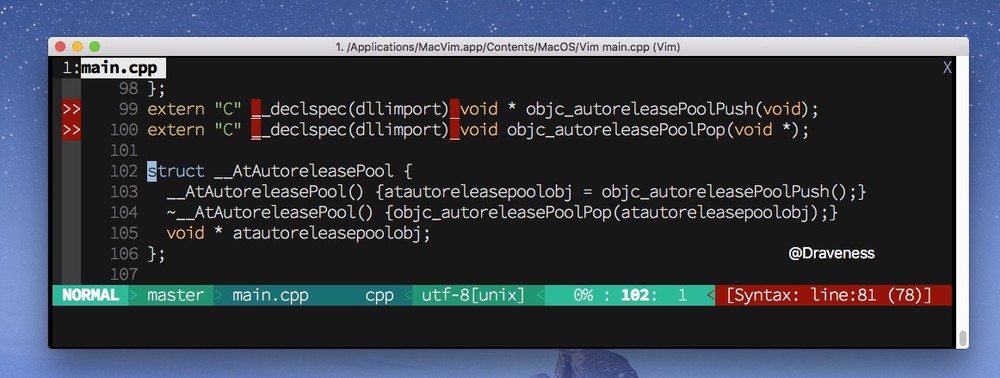
- 这个结构体会在初始化时调用 objc_autoreleasePoolPush() 方法,会在析构时调用 objc_autoreleasePoolPop 方法 push 和 pop 是对 autoreleasePoolPage进行调用
void *objc_autoreleasePoolPush(void) {
return AutoreleasePoolPage::push();
}
void objc_autoreleasePoolPop(void *ctxt) {
AutoreleasePoolPage::pop(ctxt);
}
/// C++类,可以看出双向链表
class AutoreleasePoolPage {
magic_t const magic; // magic 用于对当前 AutoreleasePoolPage 完整性的校验
id *next; //指向最新添加的 autoreleased 对象的下一个位置,初始化时指向 begin() ;
pthread_t const thread; // 当前线程
AutoreleasePoolPage * const parent;
AutoreleasePoolPage *child;
uint32_t const depth; //代表深度,从 0 开始,往后递增 1;
uint32_t hiwat; // 代表 high water mark
};
/// 调用栈
- [NSObject autorelease]
└── id objc_object::rootAutorelease()
└── id objc_object::rootAutorelease2()
└── static id AutoreleasePoolPage::autorelease(id obj)
└── static id AutoreleasePoolPage::autoreleaseFast(id obj)
├── id *add(id obj)
├── static id *autoreleaseFullPage(id obj, AutoreleasePoolPage *page)
│ ├── AutoreleasePoolPage(AutoreleasePoolPage *newParent)
│ └── id *add(id obj)
└── static id *autoreleaseNoPage(id obj)
├── AutoreleasePoolPage(AutoreleasePoolPage *newParent)
└── id *add(id obj)
看到这里返回的ret其实next指针指向的地址,由上面的push方法的源码可知,这里page->add(obj)传入的obj其实就是POOL_BOUNDARY,也就是说每一次调用push方法,都会插入一个POOL_BOUNDARY,所以objc_autoreleasePoolPush的返回值就是这个哨兵对象的地址。
static inline void *push() {
return autoreleaseFast(POOL_SENTINEL);
}
static inline id *autoreleaseFast(id obj)
{
AutoreleasePoolPage *page = hotPage();
if (page && !page->full()) {
return page->add(obj);
} else if (page) {
return autoreleaseFullPage(obj, page);
} else {
return autoreleaseNoPage(obj);
}
}
id *add(id obj)
{
assert(!full());
unprotect();
id *ret = next; // faster than `return next-1` because of aliasing
*next++ = obj;
protect();
return ret;
}
static inline id autorelease(id obj)
{
assert(obj);
assert(!obj->isTaggedPointer());
id *dest __unused = autoreleaseFast(obj);
assert(!dest || dest == EMPTY_POOL_PLACEHOLDER || *dest == obj);
return obj;
}
注:push操作并不会插入一个 POOL_BOUNDARY ,而是标记了一个 Placeholder,当下次有对象加入自动释放池时,再进行插入 POOL_BOUNDARY ,然后再插入对象 obj
POOL_SENTINEL(哨兵对象) #define POOL_SENTINEL nil
pop->releaseUntil
static inline void pop(void *token)
{
AutoreleasePoolPage *page;
id *stop;
// 如果是空池占位符,要清空整个自动释放池
if (token == (void*)EMPTY_POOL_PLACEHOLDER) {
if (hotPage()) {
// 如果存在 hotPage ,则找到 coldPage 的起点 重新 pop
pop(coldPage()->begin());
} else {
// 未使用过的释放池,置空 TLS 中存放的 hotPage
setHotPage(nil);
}
return;
}
page = pageForPointer(token);
stop = (id *)token;
if (*stop != POOL_BOUNDARY) {
// 在 stop 不为 POOL_BOUNDARY 的情况下 只可能是 coldPage()->begin()
if (stop == page->begin() && !page->parent) {
} else {
// 如果不是 POOL_BOUNDARY 也不是 coldPage()->begin() 则报错
return badPop(token);
}
}
if (PrintPoolHiwat) printHiwat();
// 释放 stop 后面的所有对象
page->releaseUntil(stop);
// 清除后续节点 page
if (page->child) {
// 如果当前 page 没有达到半满,则干掉所有后续 page
if (page->lessThanHalfFull()) {
page->child->kill();
}
// 如果当前 page 达到半满以上,则保留下一页
else if (page->child->child) {
page->child->child->kill();
}
}
}
1. 检查入参是否为空池占位符EMPTY_POOL_PLACEHOLDER,如果是则继续判断是否hotPage存在,如果hotPage存在则将释放的终点改成coldPage()->begin(),如果hotPage不存在,则置空 TLS 存储中的hotPage。
2. 检查stop既不是POOL_BOUNDARY也不是coldPage()->begin()的情况将报错。
3. 清空自动释放池中stop之后的所有对象。
4. 判断当前page如果没有达到半满,则干掉所有后续所有 page,如果超过半满则只保留下一个page。
void releaseUntil(id *stop)
{
// 当 next 和 stop 不是指向同一块内存地址,则继续执行
while (this->next != stop) {
AutoreleasePoolPage *page = hotPage();
// 如果 hotPage 空了,则设置上一个 page 为 hotPage
while (page->empty()) {
page = page->parent;
setHotPage(page);
}
page->unprotect();
id obj = *--page->next; // page->next-- 后指向当前栈顶元素
memset((void*)page->next, SCRIBBLE, sizeof(*page->next)); // 将栈顶元素内存清空
page->protect();
if (obj != POOL_BOUNDARY) {
objc_release(obj); // 栈顶元素引用计数 - 1
}
}
setHotPage(this);
}
判断栈顶指针next和stop不是指向同一块内存地址时,继续出栈。
判断当前page如果被清空,则继续清理链表中的上一个page。
出栈,栈顶指针往下移,清空栈顶内存。
如果当前出栈的不是POOL_BOUNDARY,则调用objc_release引用计数 - 1 。
解释:
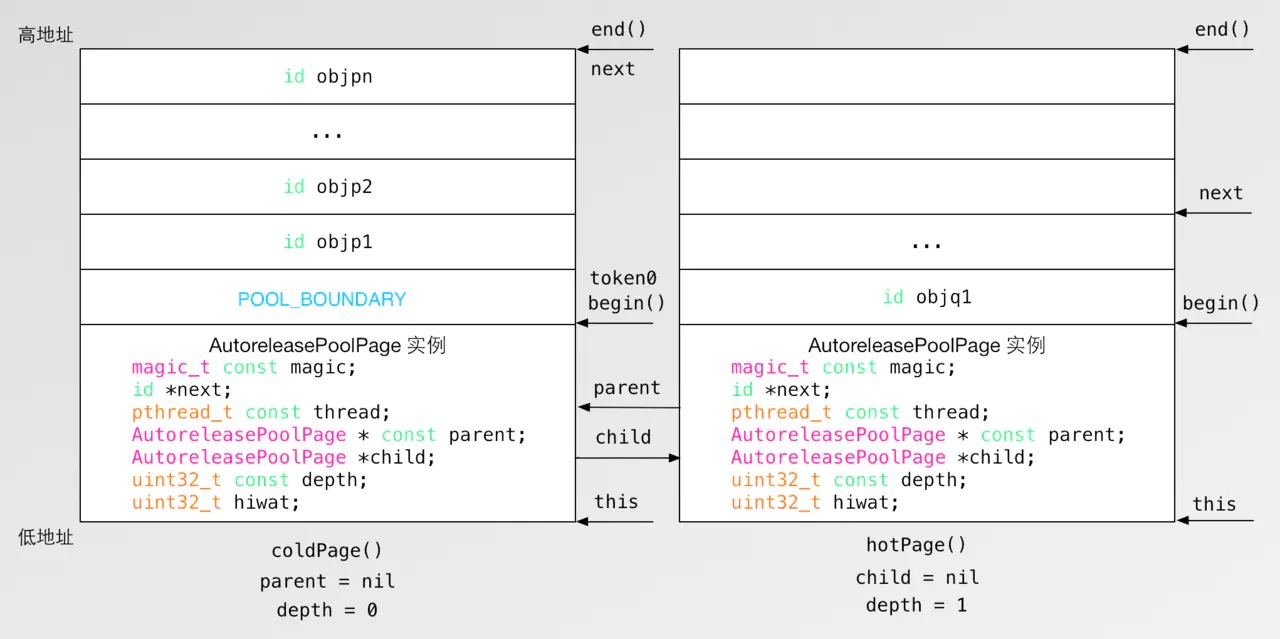
- hotPage:是当前正在使用的page,操作都是在hotPage上完成,一般处于链表末端或者倒数第二个位置。存储在 TLS 中,可以理解为一个每个线程共享一个自动释放池链表。
- coldPage:位于链表头部的page,可能同时为hotPage。
- POOL_BOUNDARY:nil的宏定义,替代之前的哨兵对象POOL_SENTINEL,在自动释放池创建时,在objc_autoreleasePoolPush中将其推入自动释放池中。在调用objc_autoreleasePoolPop时,会将池中对象按顺序释放,直至遇到最近一个POOL_BOUNDARY时停止。
- EMPTY_POOL_PLACEHOLDER:当自动释放池中没有推入过任何对象时,这个时候推入一个POOL_BOUNDARY,会先将EMPTY_POOL_PLACEHOLDER存储在 TLS 中作为标识符,并且此次并不推入POOL_BOUNDARY。等再次有对象被推入自动释放池时,检查在 TLS 中取出该标识符,这个时候再推入POOL_BOUNDARY。
- next:指向AutoreleasePoolPage空位指针,每次加入新的元素会向后移动。
AutoreleasePool的嵌套
对于嵌套的AutoreleasePool也是同样的原理,在pop的时候总会释放对象到上次push的位置为止,也就是哨兵位置,多层的pool就是插入多个哨兵对象而已,然后根据哨兵对象来进行释放,就像剥洋葱一样一层一层的,互不影响。
什么对象会被加入到autorleasePool里(看rauntime相关)
- 使用__autoreleasing 标记的
- 系统的比如NSString stringWithFormat:@”xxx“, 其他比如[NSArray array]等
注:alloc/new/copy/mutableCopy不会加入
autoreleasepush (对上面方法总结)
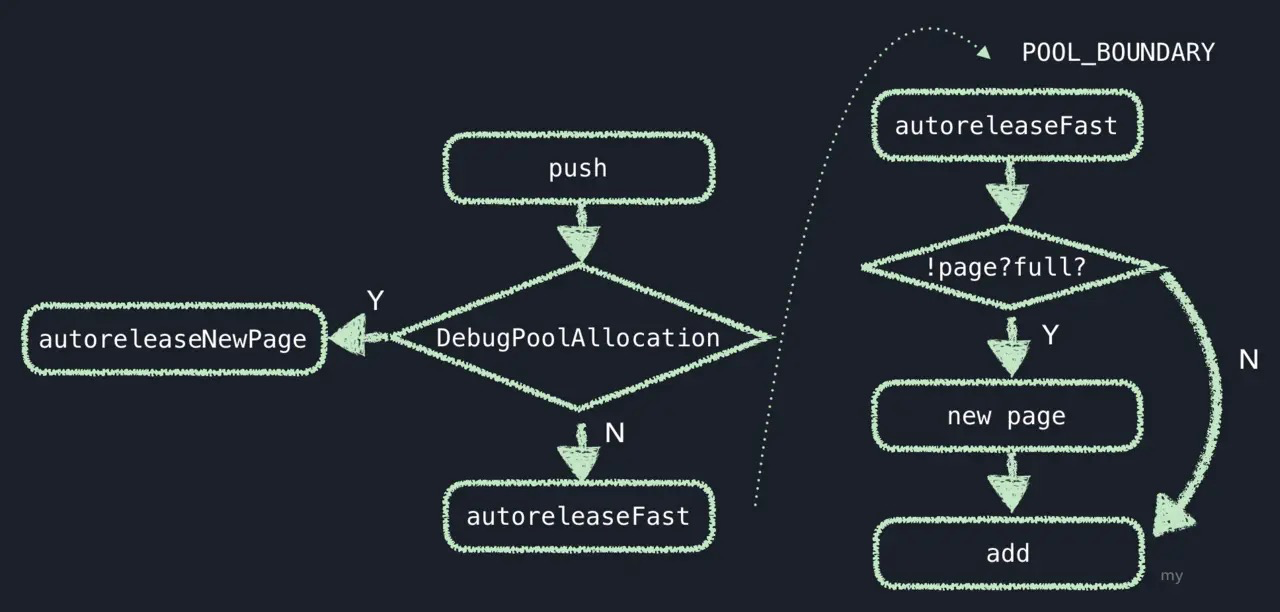
首先会类型类别,如果是需要每个pool都生成一个新page,即DebugPoolAllocation为真时, 则执行autoreleaseNewPage方法,否则,执行autoreleaseFast方法. 在autoreleaseFast方法中,如果存在page且未满,则直接添加;如果不存在page,会响应autoreleaseNoPage;如果当前page已满,则响应autoreleaseFullPage方法;autoreleaseNoPage和autoreleaseFullPage会生成新的page,然后向该page中添加对象. 而autoreleaseNewPage方法,如果当前存在page,则执行autoreleaseFullPage方法,否则响应autoreleaseNoPage方法,然后就同上了,去执行添加方法.
通过弱引用指向的对象,获取弱引用表,并且将其上锁,防止在此期间被清除。 判断是否包含自定义retain方法,如果没有,则使用默认rootTryRetain方法,使引用计数 + 1 。 如果使用了自定义retain方法,则调用自定义方法,在调用之前会先判断该对象所属类是否已经初始化过,如果没有初始化会先进行初始化然后再调用。
autorelease 和线程的关系
- 使用nsthread创建的线程,默认不会添加autoreleasepool,但里面如果使用了__autoreleasing 或子线程在使用autorelease对象时,如果没有autoreleasepool会在autoreleaseNoPage中懒加载一个出来。
2.在runloop的run:beforeDate,以及一些source的callback中,有autoreleasepool的push和pop操作,总结就是系统在很多地方都差不多autorelease的管理操作。
3.就算插入没有pop也没关系,在线程exit的时候会释放资源,执行AutoreleasePoolPage::tls_dealloc,在这里面会清空autoreleasepool。
__strong __weak (runtime相关也有一份更详细的)
strong 在llvm编译器转换成下面的代码 id attribute((objc_ownership(strong))) obj = ((NSObject ()(id, SEL))(void )objc_msgSend)((id)((NSObject *()(id, SEL))(void *)objc_msgSend)((id)objc_getClass(“NSObject”), sel_registerName(“alloc”)), sel_registerName(“init”)); 即会调用:
id obj = objc_msgSend(NSObject, @selector(alloc));
objc_msgSend(obj,selector(init));
objc_release(obj);
id weak obj = strongObj; 转成 id __attribute((objc_ownership(none))) obj1 = strongObj; 即调用
id obj ;
objc_initWeak(&obj,strongObj);
objc_destoryWeak(&obj);
//
id objc_initWeak(id *object, id value) {
*object = nil;
return objc_storeWeak(object, value);
}
void objc_destroyWeak(id *object) {
objc_storeWeak(object, nil);
}
由于weak表也是用Hash table实现的,所以objc_storeWeak函数就把第一个入参的变量地址注册到weak表中,然后根据第二个入参来决定是否移除。如果第二个参数为0,那么就把__weak变量从weak表中删除记录,并从引用计数表中删除对应的键值记录。
所以如果__weak引用的原对象如果被释放了,那么对应的__weak对象就会被指为nil。原来就是通过objc_storeWeak函数这些函数来实现的。
alloc, copy, ,mutableCopy和new这些方法会被默认标记为 __attribute((ns_returns_retained))
指针
dirty memory 与clean meory如何区分
clean memory加载后不会发生变化, class_ro_t属于clean memory,(新创建的固定长度的数组,预先占用的内存也是clean memory) 只读的,收到内存警告后可以由系统进行销毁,再次创建。 Dirty memory是运行时进行修改的内存块。类一旦被加载,就是dirty memory。runtime给类动态添加方法,都是操作的dirty memory. class_rw_t属于 dirty memory, 对开发者来说,越多的clean memory,越好 Dirty memory 比clean 更昂贵,它需要更多的内存信息,并且只要进程正在运行,就必须保留它。 class_rw_t是在 runtime期间创建的,它将class_ro_t内容copy一份,再将类的分类,动态加载的属性、方法、协议添加进去。苹果在iOS14 将动态部分提取出来,称为 class_rw_ext_t,可以吧90%的类优化为clean memory 在系统层面上节约了14MB的内存。
malloc
承接runtime的alloc方法,
malloc内存分配基于malloc zone,并将基于大小分为nano、tiny、small、large四种类型,申请时按需分配.具体信息如下图:
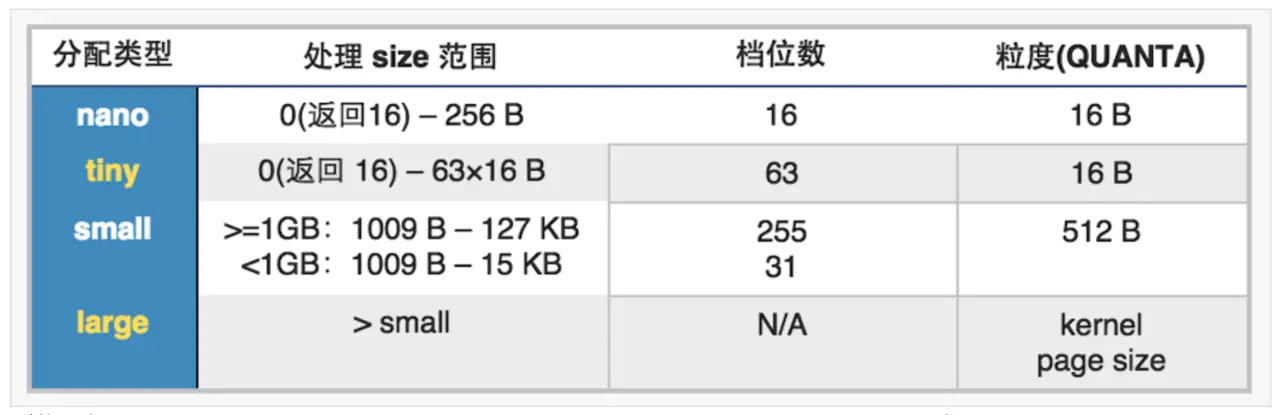
malloc在初次调用时,会分配一个default zone和一个scalable zone作为辅助,在64位环境下,default zone为nano zone,负责分配nano大小,scalable zone负责tiny、small和large内存的分配.
malloc vs calloc
malloc的内存分配当然也是先分配虚拟内存,然后使用的时候再映射到物理内存,不过malloc有一个缺陷,必须配合memset将内存区中所有的值设置为0。这样就导致了一个问题,malloc出一块内存区域时,系统并没有分配物理内存。然而,调用memset后,系统将会把malloc出的所有虚拟内存关联到物理内存上,因为你访问了所有内存区域。

官方推荐使用calloc代替malloc,calloc返回的内存区域会自动清零,而且只有使用时才会关联到物理内存并清零。 文章链接
allocWithZone或者copyWithZone这2个方法大家应该也经常见到。那么Zone究竟是什么呢?Zone可以被理解为一组内存块,在某个Zone里分配的内存块,会随着这个Zone的销毁而销毁,所以Zone可以加速大量小内存块的集体销毁。不过NSZone实际上已经被苹果抛弃。
NSZone *customZone = NSCreateZone(1024, 1024, YES);
NSSetZoneName(customZone, @"Custom Object Zone");
one Custom Object Zone_0x1004fe000: 1 nodes (32 bytes)就是我们创建的NSZone,不过它里面只有一个节点,共32bytes,如果你不设置Zone的name,它会是0bytes。所以我们可以推导出这32bytes是用来存储Zone本身的信息的 使用allocWithZone创建的对象,对象内存都在系统默认的DefaultMallocZone_0x1004c9000里
真的想用Zone内存机制,可以使用malloc_zone_t
void allocCustomObjectsWithCustomMallocZone() {
malloc_zone_t *customZone = malloc_create_zone(1024, 0);
malloc_set_zone_name(customZone, "custom malloc zone");
for (int i = 0; i < 1000; ++i) {
malloc_zone_malloc(customZone, 300 * 4096);
}
}
TLS,Thread Local Storage
线程局部存储,也就是将一块内存作为某个线程专属的存储,同一线程的多个pool共享这个存储区域.那么这个区域具体存储什么呢?上文__strong的实现中我们提到,对于自己不持有的对象,系统会自动插入的一个命令objc_retainAutoreleasedReturnValue,与之对应的还有objc_retainAutoreleasedReturnValue objc_autoreleaseReturnValue.更详细的优化命令如下图:
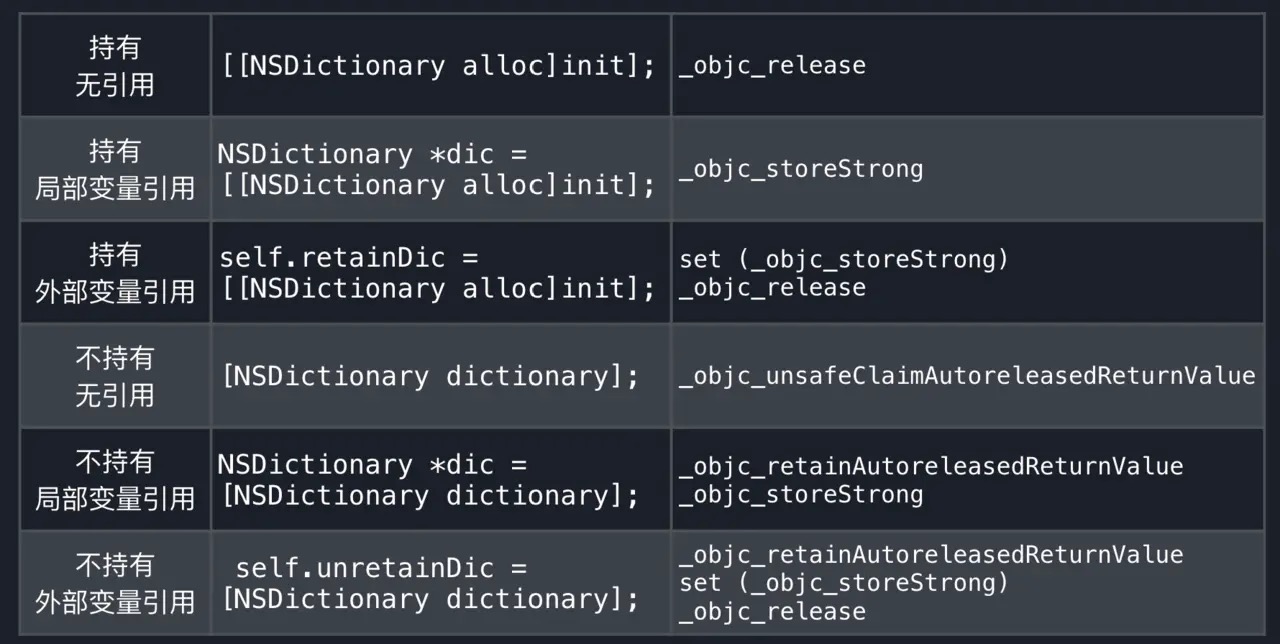
autorelase的优化
id objc_retainAutoreleasedReturnValue(id obj)
{
if (acceptOptimizedReturn() == ReturnAtPlus1) return obj;
return objc_retain(obj);
}
id objc_autoreleaseReturnValue(id obj)
{
if (prepareOptimizedReturn(ReturnAtPlus1)) return obj;
return objc_autorelease(obj);
}
其中的acceptOptimizedReturn 和prepareOptimizedReturn是优化标识,而优化标识和优化对象就是存储在TLS上的.当可以优化时,直接从TLS上返回当前对象地址,而不执行retain与release操作.比如对同一个对象进行retain操作后又进行release操作,那么这两个操作都不会执行.
dyld的共享缓存
当你构建一个真正的程序的时候,你将会链接各种各样的库。它们又会依赖其他的一些框架和动态链接库。于是要加载的动态链接库会非常多。同样非独立的符号也非常多。这里就会有成千上万的符号要确定。这个工作将会话费很多时间——几秒钟。 为了优化这个过程,OS X和iOS上动态链接器使用了一个共享缓存,在/var/db/dyld/。对于每一种架构,操作系统有一个单独的文件包含了绝大多数的动态链接库,这些库已经互相连接并且符号都已经确定。当一个Mach-o文件被加载的时候,动态链接器会首先检查共享缓存,如果存在相应的库就是用。每一个进程都把这个共享缓存映射到了自己的地址空间中。这个方法戏剧性的优化了OS X和iOS上程序的加载时间。
Runtime优化
类数据结构变化: First Subclass 和 Next Sibling Class 指针让运行时可以遍历当前使用的所有类。 Methods 、 Properties 、 Protocols ,这部分也是可以在运行时进行修改的。在实践中发现,其实只有大约10%类的方法会发生变化,所以这部分内存可以得到优化,滕出一些空间。 Demangled Name 只会被Swift类所使用,而且除非有需要获取它们的Objective-C名称,甚至都不会用到。
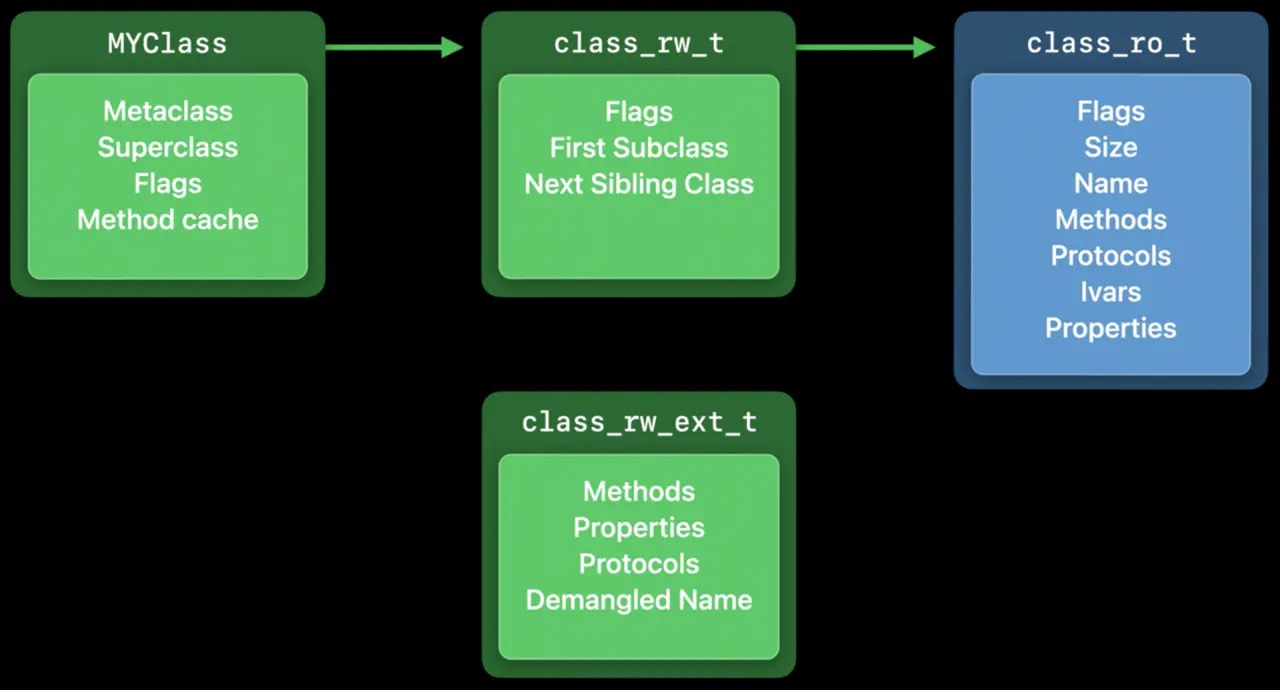 这样就把class_rw_t,拆成了2部分。如果确实有需要,我们才会这部分class_rw_ext_t结构分配内存。大约90%的类都不需要这部分额外的数据,系统就可以节约大概14MB的内存
这样就把class_rw_t,拆成了2部分。如果确实有需要,我们才会这部分class_rw_ext_t结构分配内存。大约90%的类都不需要这部分额外的数据,系统就可以节约大概14MB的内存
| tips:head xxxxx | egrep ‘class_rw | COUNT’ 你可以使用此命令来查看 class_rw_t 消耗的内存。xxxx可以替换为需要测量的 App 名称。如:head Mail | egrep ‘class_rw | COUNT’'查看 Mail 应用的使用情况。 |
方法列表变化: 方法列表是存在于镜像中的,而镜像的加载位置可能在内存的任何地方,这取决于动态链接器的选择。也就是说,链接器需要解析镜像中的指针,修复它们指向内存真实的的位置。这部分会产生额外的消耗。 又由于镜像中的方法都是固定的,不会跑到其他镜像中去。其实我们不需要64位寻址的指针,只需要32位即可。
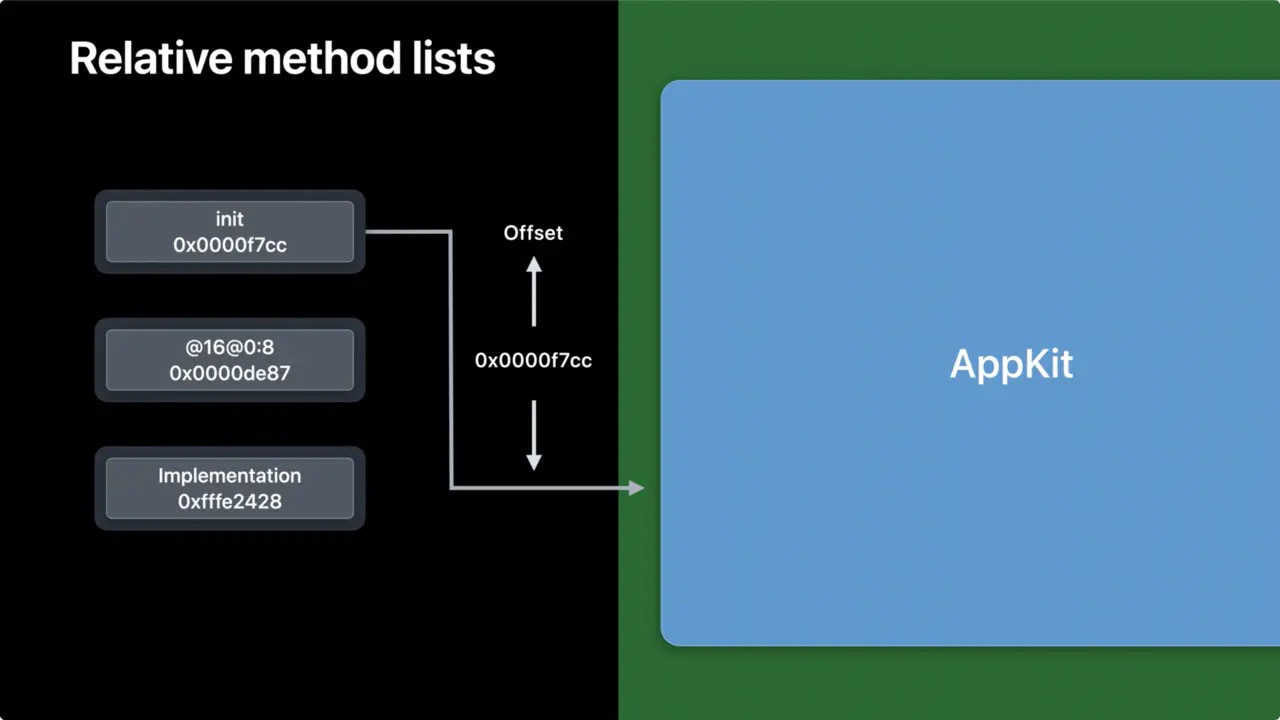 这样做有几个好处:
这样做有几个好处:
这个偏移量相对镜像是固定的,与镜像加载的位置无关,当它们从磁盘加载进来后就不要进行修复了。 因为不再需要进行修复了,这部分数据就可以保存在只读内存(Clean Memory )中,这样也更安全。 在64位系统中,指针大小从64位的24字节下降到32位的12字节。根据实际测量,方法列表占用内存大约为80MB,减半的话就可以节约40MB内存。 如果我们使用了 Method Swizzling 苹果会在一个全局表中映射交换的实现。由于交换并不是非常常见的操作,所以这个全局表也不会特别大。
Tagged Pointer 格式的变化
内存对齐要求的存在,低位始终为0,对象必须始终位于指针大小倍数的地址中。高位也始终为0。实际上我们只是用中间这一部分的位。
 Intel
Intel
 ARM64
ARM64

GCD的卡顿问题,dispatch_async
阅读过 GCD 源码的同学会知道,所有默认创建的 GCD queue 都有一个优先级,但其实每个优先级对应两个 queue,比如一个是 default-priority, 那么另一个就是 default-priority-overcommit。dispatch_async 的时候,会首先将任务丢进 default-priority 队列,如果队列满了,就转而丢进 default-priority-overcommit。 在 Mac 系统里,GCD 允许 overcommit,意味着每次 dispatch_async 都会创建一个新线程,即使 over commit 了,这些过量的线程会根据优先级来竞争 CPU 资源。
而在 iOS 系统里,GCD 会控制 overcommit,如果某个优先级队列 over commit 里,那么排在后面的任务就会处于等待状态。移动设备 CPU 资源比较紧张,这种设计合乎常理。
所以如果在 iOS 里创建过多的 serial queue,那么后面提交的任务可能就会一直处于等待状态。这也是为什么我们需要严格控制 queue 的数量和层级关系,最好是 App 当中每个子系统只能分配固定数量和优先级的 queue,从而避免 thread explosion 导致的代码无法及时执行问题
信息一 iOS 系统本身是一个资源调度和分配系统,CPU,disk IO,VM 等都是稀缺资源,各个资源之间会互相影响,主线程的卡顿看似 CPU 资源出现瓶颈,但也有可能内核忙于调度其他资源,比如当前正在发生大量的磁盘读写,或者大量的内存申请和清理,都会导致下面这个简单的创建线程的内核调用出现卡顿:
libsystem_kernel.dylib __workq_kernreturn
所以解决办法只能是自己分析各 thread 的 call stack,根据用户场景分析当前正在消耗的系统资源。后面也确实通过最近提交的代码分析,发现是由于增加了一些非常耗时的磁盘 io 任务(虽然也是放在在子线程),才出现这个看着不怎么沾边的 call stack。revert 之后卡顿警报就消失了。
信息二
现有的卡顿检测工具都只能在超时的情况下 dump call stack,但出现超时有可能是任务 A,B,C 共同作用导致的,A 和 B 可能是真正耗时的任务,C 不耗时但碰巧是最后一个,所以被当成元凶,而 A 和 B 却没有出现在上报日志里。我暂时也没有想到特别好的解决办法。很明显,libsystem_kernel.dylib __workq_kernreturn 就是一个不怎么耗时的 C 任务。
信息三
在使用 GCD 创建 queue,或者说一个 App 内部使用 GCD 执行子线程任务时,最好有一套 App 所有团队都能遵循的队列使用机制,避免创建过多的 thread,而出现意料之外的线程资源紧缺,代码无法及时执行的情况。这很难,尤其是在大公司动则上百人的团队里面。